We read the recent whitepaper: “Sortino: A Sharper Ratio” by Red Rock Capital with great interest. You see, as we’ve discussed before, the Sharpe ratio is both one of the most accepted and at the same time most critiqued forms of performance measurement in the managed futures world. The better ratio for many, including us – is the Sortino ratio, which doesn’t penalize programs for outlier gains as the Sharpe ratio does.
Here’s a little recap on the two… Sharpe measures Return divided by (upside and downside) volatility, while the Sortino measures Return divided by (downside) volatility only.
 Graph Courtesy: Red Rock Capital
Graph Courtesy: Red Rock Capital
The general way we’ve seen the Sharpe and Sortino ratios calculated is as follows, with the Sharpe’s denominator the standard deviation of all returns, and the Sortino’s the standard deviation of all negative returns. Seems simple enough:
“Sharpe = (Compound ROR – risk free ROR) / (Standard Deviation of Returns)”
“Sortino = (Compound ROR – risk free ROR) / (Standard Deviation of Negative Returns)”
But is the industry as a whole using the Sortino ratio correctly? Our friends at Red Rock Capital don’t think so, saying in their recent paper:
“We believe the Sortino ratio improves on the Sharpe ratio in a few areas. [But] the purpose of this article…is not necessarily to extol the virtues of the Sortino ratio, but rather to review its definition and present how to properly calculate it since we have often seen its calculation done incorrectly.”
Red Rock states the real definition of the Sortino ratio uses not the standard deviation of negative returns, but instead the ‘target downside deviation’, which is the deviations of the realized return’s underperformance from the target return. What does that mean to the normal person who has trouble reading math equations? Well, it means the usual method of throwing away all the positive returns and taking the standard deviation of negative returns isn’t technically correct, as it ignores the fact that you’re supposed to be looking at just the below target return deviations. As Red Rock puts it:
“Standard deviation is a measure of dispersion of data around its mean, both above and below. Target Downside Deviation is a measure of dispersion of data below some user selectable target return with all above target returns treated as underperformance of zero. Big difference.
The [correct] Sortino ratio takes into account both the frequency of below target returns as well as the magnitude of below target returns. [The normal way of] throwing away the zero underperformance data points removes the ratio’s sensitivity to frequency of underperformance. Consider the following underperformance return streams: [0, 0, 0, -10] and [-10, -10, -10, -10]. Throwing away the zero underperformance data points results in the same target downside deviation for both return streams, but clearly the first return stream has much less downside risk than the second.”
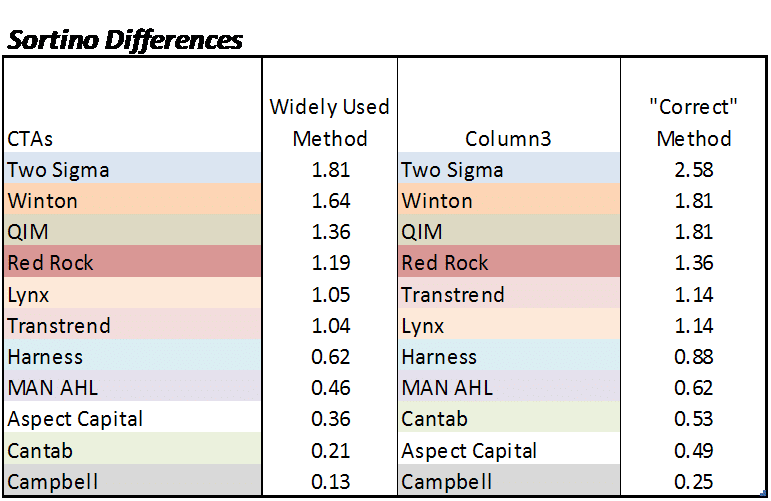
Which method is correct? We will take Red Rock’s word for it that this is how the equation was originally written up – but we also know that the other method is quite widely used (our own website, for example). Surely there is value in the widely used method, but Red Rock makes some excellent points on the issues therein. So, we looked at a few programs (the 10 largest CTAs as of June 2013 plus Red Rock) to see what differences were there between the widely used Sortino method and Red Rock’s “correct” method.
(Disclaimer: Past performance is not necessarily indicative to futures results)
Above stats from Sept. ’03 through Jul. ’13, excepting the following:
Two Sigma from Jan. ’05, Cantab from March ’08, Harness from April ’09
You can see the value of the Sortino rose in each program on our list by using the calculation outlined by Red Rock, but we know that Sortino values don’t really mean all that much. The measure is better used as a way to compare the risk adjusted performance of programs with differing risk and return profiles. Any risk adjusted ratio is really trying to just normalize the risk across programs, and then see which has the higher return per that normalized unit of risk.
So, when considering not the value of the ratio when changed, but what the changed value does to a ranking by Sortino ratio of the world’s biggest managed futures programs – what do we see? Not much, to be honest, as the top four remained in the same order. However, there was some movement in the rankings, Transtrend and Lynx switching places, as well as Aspect and Cantab, but the ranking is pretty close across the two calculation methods.
So, as a practical matter – this doesn’t really move the needle that much, and is likely a more useful tool when analyzing unique track records where all monthly losses are exactly -%5 or the like. The real discovery here seems to be Red Rock Capital – who sports a higher Sortino than some of the royalty of managed futures (i.e. AHL, Campbell, Transtrend) no matter which method is used.
You can view the full paper here: Sortino: A Sharper Ratio



